 On Wednesday, the focus of the general session was on IBM’s
acquisition of The Weather Company’s technology. The deal calls for IBM to acquire The Weather
Company’s B2B, mobile and cloud-based web properties, including WSI, weather.com,
Weather Underground and The Weather Company brand. IBM will not be acquiring The
Weather Channel television station, which will license weather forecast data
and analytics from IBM under a long-term contract. IBM intends to utilize its newly
acquired weather data in its Watson platform.
On Wednesday, the focus of the general session was on IBM’s
acquisition of The Weather Company’s technology. The deal calls for IBM to acquire The Weather
Company’s B2B, mobile and cloud-based web properties, including WSI, weather.com,
Weather Underground and The Weather Company brand. IBM will not be acquiring The
Weather Channel television station, which will license weather forecast data
and analytics from IBM under a long-term contract. IBM intends to utilize its newly
acquired weather data in its Watson platform.
The deal is expected to close in the first quarter of 2016.
Terms were not disclosed.
I spent some of my time at
Insight this year learning more about dashDB and it is a very interesting
technology. Marketed as data warehousing in the cloud, IBM touts four use cases
for dashDB: standalone cloud data warehouse, as a store for data scientists, for
those implementing a hybrid data warehouse, and for NoSQL analysis and rapid
prototyping.
IBM promotes simplicity,
performance, analytics on both traditional and NoSQL, and polyglot language
support as the most important highlights of dashDB. And because it has DB2 BLU
under the covers IBM dashDB not only super-compresses data, but it can operate
on that data without necessarily decompressing it.
Additionally, a big theme of
the conference was in-memory technology, and dashDB sports CPU cache
capabilities. In fact, I heard several folks at the conference say some
variation of “RAM is too slow”… meaning that CPU cache is faster and IBM is moving
in that direction.
The bottom line for dashDB is
that it offers built-in high availability and workload management capabilities,
along with being in-memory optimized and scalable. Worth a look for folks
needing a powerful data warehousing platform.
For you DB2 for z/OS folks, IDAA
was a big theme of this year’s Insight conference. The latest version, V5.1,
adds advanced analytics capabilities and in database transformation, making
your mainframe queries that can take advantage of the accelerator faster than
ever.
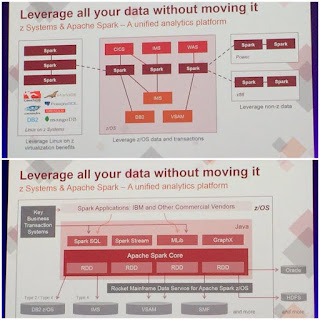 Apache Spark was another
pervasive topic this year. It was talked about in multiple sessions and I even
had the opportunity to play with it in a hands-on lab. The big news for z folks
is that IBM is bringing out a version of Spark for the mainframe that will run
on z/OS – it is already supported on zLinux.
Apache Spark was another
pervasive topic this year. It was talked about in multiple sessions and I even
had the opportunity to play with it in a hands-on lab. The big news for z folks
is that IBM is bringing out a version of Spark for the mainframe that will run
on z/OS – it is already supported on zLinux.
Of course, I attended a whole
slew of DB2 sessions including SQL coding, performance and administration
presentations. Some of the highlights include DB2 11 for LUW being announced, several discussions about dark data, and a lot of information about IBM's Big SQL and how it can be used to rapidly and efficiently access Hadoop (and other unstructured) data using SQL.
I live-tweeted a bunch of highlights of those sessions, too. Indeed, too many to include here, if you are
interested in catching everything I have to say about a conference, keep
reading these blog posts, of course, but you should really follow me on
Twitter, too at http://twitter.com/craigmullins
I also had the honor of delivering a presentation at this year's conference on the changes and trends going on in the world of DB2 for z/OS. Thanks to the 70 or so people who attended my session - I hope you all enjoyed it and learned something, too!
 As usual, and well-you-know if you've ever attended this conference before, there was also a LOT of walking to be done. From the hotel to the conference center to the expo hall to lunch to the conference center. But at least there were some signs making light of the situation this year!
As usual, and well-you-know if you've ever attended this conference before, there was also a LOT of walking to be done. From the hotel to the conference center to the expo hall to lunch to the conference center. But at least there were some signs making light of the situation this year!
There was a lot of fun to be
had at the conference, too. The vendor exhibition hall was stocked with many
vendors, big and small, and it seems like they all had candy. I guess that’s
what you get when the conference is so close to Halloween! The annual Z party
at the House of Blues (for which you need a Z pin to get in – this year’s pin
was orange) was a blast and the Maroon 5 concert courtesy of Rocket Software
was a lot of fun, too.
If you are looking for a week
of database, big data, and analytics knowledge transfer, the opportunity to
chat and connect with your peers, as well as some night-time entertainment, be
sure to plan to attend next year’s IBM Insight conference (October 23 thru 27,
2016 at the Mandalay Bay in Las Vegas).





